TL;DR
Artificial Intelligence and Machine Learning center around the idea of computers simulating “smart” actions, but they differ in scope. Artificial Intelligence broadly represents a machine’s ability to perform human tasks (including process automation as well as cognitive automation). Machine Learning is one application of AI that focuses on allowing a computer to discover patterns without explicit programming other than initial input parameters and data (or the ability to create data). Read below for background and a code-along example of Machine Learning.
Background
The terms “Artificial Intelligence” and “Machine Learning” were coined way back in the 1950s, but recent increases in processing power have made the terms more relevant now than ever. Computers have beaten the best humans in the world at complex games like Chess and Go, cars are on the verge of driving themselves, and it all seems to be due to the magic of Machine Learning. Senior research scientist at Google, Greg Corrado, says “It’s not magic. It’s just a really important tool” that will soon permeate most aspects of society. But as nice as it would be to doze off during our morning commutes, others warn against the threats that come with AI. President Obama released a report in December of 2016 discussing the potential impact it could have on our labor force, and Elon Musk continually makes known his opinion that AI poses an “existential threat” to civilization. But before we judge its efficacy, what exactly do these terms mean?
To answer that, let’s look first at their earliest definitions:
- At the first academic conference on the subject in 1956, John McCarthy offered the far-sighted, yet vague definition of Artificial Intelligence as the “science and engineering of making intelligent machines.”
- In 1959, Arthur Samuel defined Machine Learning as “a field of study that gives computers the ability to learn without being explicitly programmed.”
The second definition is a little more explicitly stated, but each term is defined using the words within the terms itself. What exactly does it mean for a computer to “learn” or be “intelligent”? None refute a computer’s ability to process logic, but those terms seem to imply thinking, which is another ballgame. Around the same time as McCarthy and Samuel, Alan Turing famously developed a test of machine “intelligence”. He hypothesized that an appropriately programmed computer with enough inputs and outputs would be able to imitate a human (through written correspondence) without detection. John Searle refuted this idea that mimicry passes for “intelligence” with this 1980s Chinese room thought experiment. In his thought experiment, Searle hypothesizes a machine that could pass the Turing test in Chinese and posits that by following the same processes as the machine, he (a non-Chinese speaker) would also pass the Turing test without any understanding of the exchange. His point is to say that while a computer can simulate intelligence, it lacks a conscious understanding (for now!). Before we get too philosophical with this (what is our mind other than a collection of data inputs collected through experience?), let’s recap: We know Artificial Intelligence and Machine Learning are not actual thinking, so then what are they?
Definition
They both center around the idea of computers simulating “smart” actions, but differ in scope. While Artificial Intelligence broadly represents a machine’s ability to perform human tasks (including process automation as well as cognitive automation). Machine Learning is one application of Artificial Intelligence that focuses on allowing a computer to discover patterns without explicit programming (aside from initial input parameters and access to data… or ability to create data as we will see below). How you ask? Let’s illustrate through an example (code here if you want to follow along):
Example
Suppose we want to develop a program to play Tic-Tac-Toe optimally. Because of the simplicity of the game, we could likely hard code the optimal response to each combination of moves, but it would be a painstaking process. Alternatively, we could use Machine Learning to create the ultimate player. First we would import the parameters of the game: create the board, the win scenarios, the alternating turns, etc. Since we don’t have any game data collected (I must have thrown out all those old cocktail napkins), at first our move will be at random. Once we have enough examples of play, we will later use those outcomes to inform our selections.
Step 1. Below are two images. On the left is an example of what our board looks like after each turn of play – each available space labeled with a number between 0-8 and marked with an “X” or “O” once selected. And on the right is an example of how we will store that game’s data – a “result” column recording the game outcome with 0 for a loss, 0.5 for a draw, or 1 for a win; a “sit” column marking the unique situation or combination of moves at that point in the game; and a “turn” column marking a turn count starting at 0. Lines 8 – 148 in the code.

Step 2. Now we’ll simulate 1000 games using random selections and store the data as our training set for future simulations. Below are two images. On the left is the distribution of results after these first thousand games. And on the right are the means of the result across each of the first selections. As you can see on the left, when randomizing selections, a winning result (1.0) occurs twice as often as a loss (0.0) and six time as often as a draw (0.5). Also notice on the right that all first selections average above 0.5, meaning that going first will likely result in a win, with the highest likelihood occurring when the the middle spot (4) is selected. Lines 149-157 in the code.

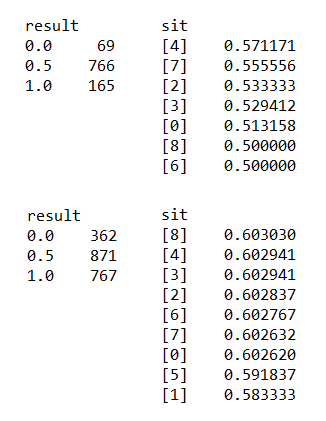
Step 3. Next we’ll simulate another 1000 games, but this time instead of randomizing the selections, we’ll use the data from our previous simulations to inform each selection. Situations that resulted in a win in the past will be prioritized and situations that resulted in a loss will be avoided. Below are 2 sets of the same two images shown above. The first set shows the results from the most recent simulation set. The second set shows the cumulative results (our training set). Notice how different the results from the informed selection simulations (below) are from the randomized simulations (above). As you can see on the left, the majority of games now end in a draw (0.5). Lines 158-169 in the code.
Step 4. We’ll simulate another 1000 games using our cumulative training set to inform our selections, and again display the results below. Notice how the results are converging to 0.5, meaning that almost all of the games are now resulting in a draw. Lines 170-181 in the code.

Step 5. We’ll simulate a final 1000 games using our cumulative training set to inform our selections, and display the results below. Notice that all simulations in this set are draws. At this point, our program never loses a game, therefore playing optimally. Lines 182-192 in the code.

Summary
While applications of Machine Learning can get much more complex than this one, this Tic-Tac-Toe use case should provide a clearer picture of what Machine Learning is, really. Rather than hard coding processes based on all possible game situations, as McCarthy, Samuel, Turing, Searle, and other AI pioneers may have imagined, we allow the computer to sift through historical data to inform its decision making. This historical data will contain explanatory variables (in this case “sit” and “turn”) and a response (in this case “result”). We can apply any number of statistical methods (in this case a simple mean on the situational universe) on the explanatory variables to predict the response. And that’s Machine Learning!
